Cummax
This transform goes row by row in a column and calculates the cumulative maximum by taking the highest value seen up to the current point. It compares each value to the previous cumulative maximum and updates the cumulative maximum value if a higher value is found. For instance, there are 1, 6, 2 as row values in a column. The first number 1 is the cumulative maximum so far. The second number 6 is higher than the previous value of 1, therefore the cumulative maximum is updated to 6.
tags: [“EDA”]
Parameters
The table gives a brief description about each parameter in Cummax transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Input Dataset:
The file name of the input dataset. You can select the dataset that was uploaded from the drop-down list. (Required: True, Multiple: False)
- Output Dataset:
The file name with which the output dataset is created after performing the cumulative maximum transform on the input dataset. (Required: True, Multiple: False)
The sample input for this transform looks as below:
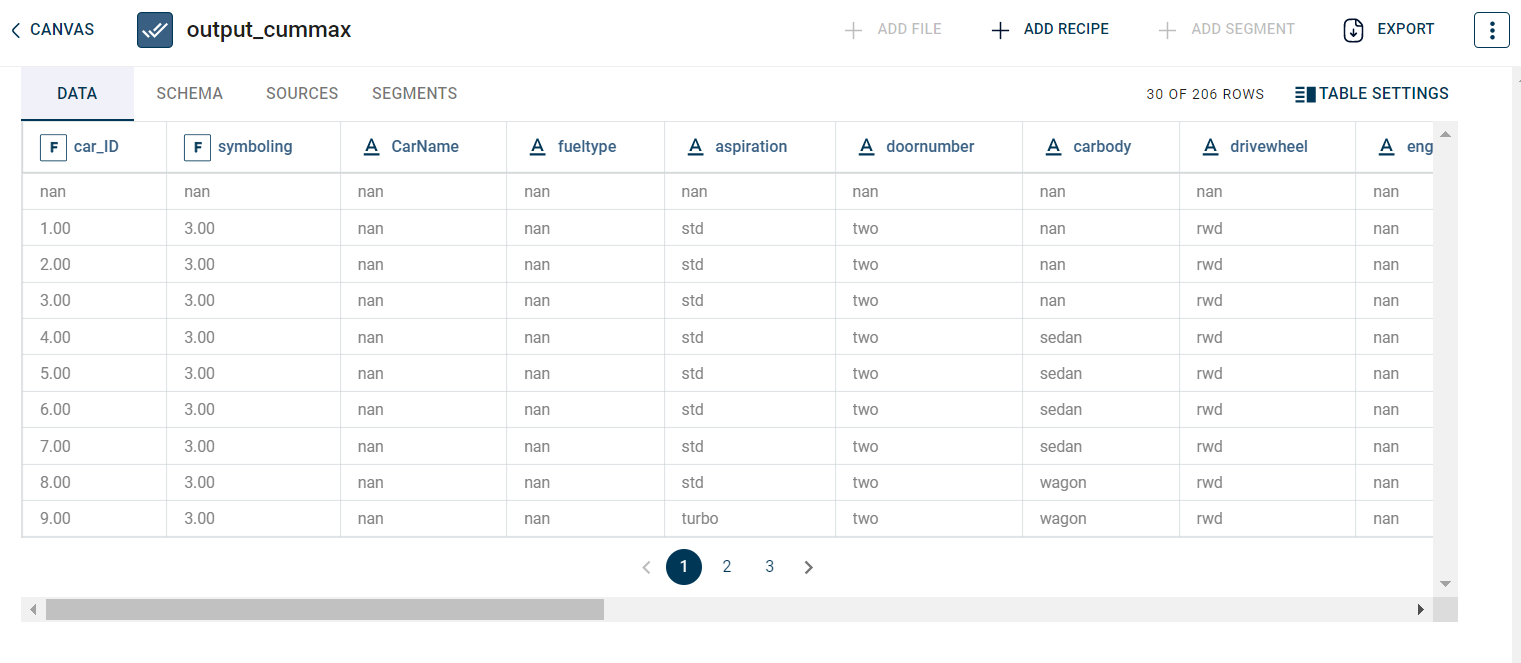
The output after running the Cummax transform on the dataset appears as below:
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Cummax transform:
template=TemplateV2.get_template_by('Cummax')
recipe_Cummax= project.addRecipe([car_data, employee_data, temperature_data, only_numeric], name='Cummax')
transform=Transform()
transform.templateId = template.id
transform.name='Cummax'
transform.variables = {
'input_dataset':'car',
'output_dataset':'car_cummax'}
recipe_Cummax.add_transform(transform)
recipe_Cummax.run()
Requirements
pandas