Group by column mean
This transform allows you to group data based on a particular column and then calculate the average value of another column within each group.
tags: [“EDA”]
Parameters
The table gives a brief description about each parameter in Group by column max transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Input Dataset:
The file name of the input dataset. You can select the dataset that was uploaded from the drop-down list. (Required: True, Multiple: False)
- Output Dataset:
The file name with which the output dataset must be generated. This file contains the group by mean values in each column. (Required: True, Multiple: False)
- Columns for grouping:
The column in which same values must be grouped to return mean value of this group in every other column. (Required: True, Multiple: False, Datatypes: [“STRING”], Options: [“FIELDS”], Datasets: [“df”])
The sample input for this transform looks as shown in the screenshot.

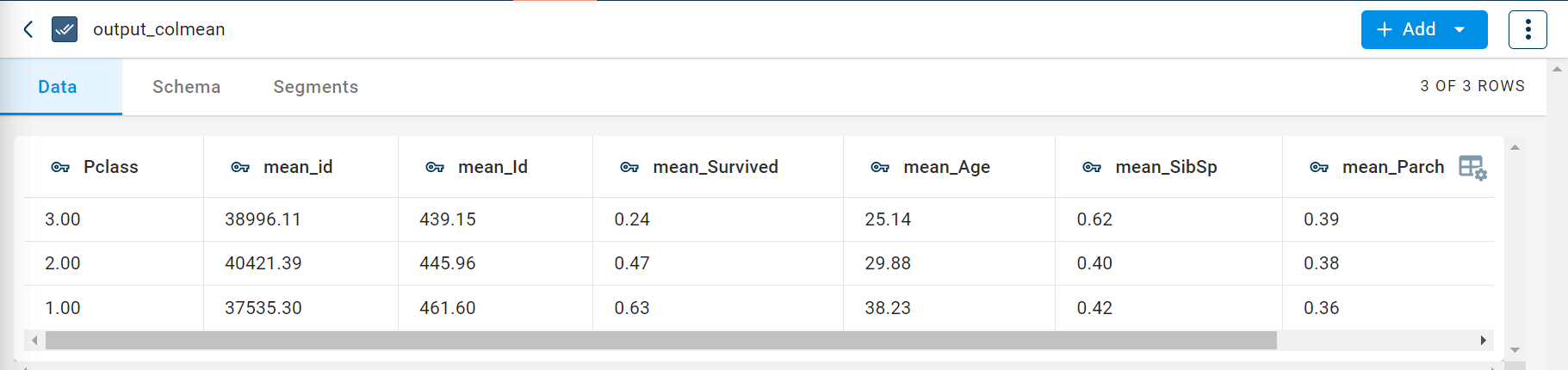
The output after running the Group by column mean transform on the dataset appears as below:
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Group by column mean transform:
template=TemplateV2.get_template_by('Group by column mean')
recipe_Group_by_column_mean= project.addRecipe([car_data, employee_data, temperature_data, only_numeric], name='Group by column mean')
transform=Transform()
transform.templateId = template.id
transform.name='Group by column mean'
transform.variables = {
'input_dataset':'car',
'output_dataset':'groupedby_car_mean',
'col1':"fueltype"}
recipe_Group_by_column_mean.add_transform(transform)
recipe_Group_by_column_mean.run()
Requirements
pandas