Tsfresh features
This transform allows you to extract all the time series features from a clean dataset.
Pre-requisites
You must configure these versions of numpy and tsfresh packages in global variables while creating the environment in which you want to run this transform:
numpy==1.21.5
tsfresh==0.20.0
tags: [“Feature Engineering”]
Parameters
This table provides a brief description about each parameter in Tsfresh features transform.
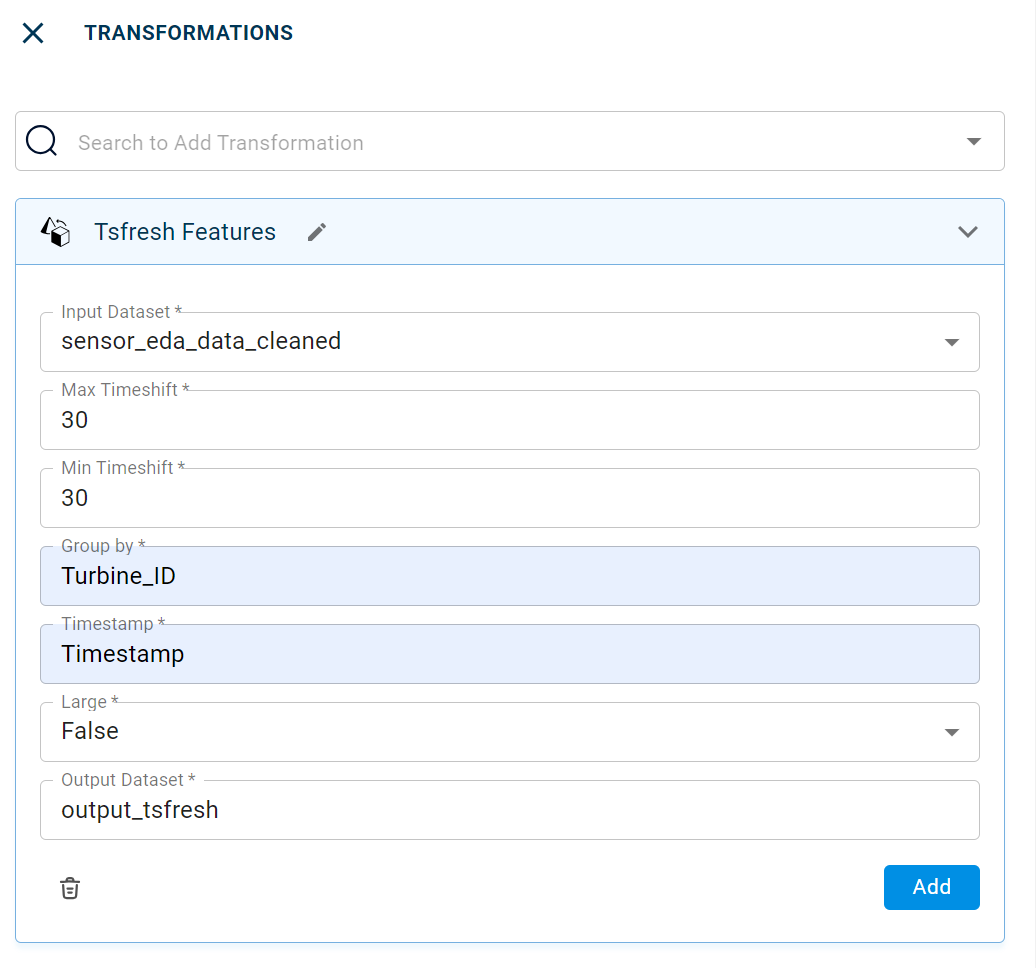
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Input Dataset:
The file name of the input dataset on which Tsfresh transform must be applied. You can select the dataset that was uploaded from the drop-down list.
- Max Timeshift:
The maximum value at which the window will be looked at in the past for each observation. If the max_timeshift is set to 30, then all windows from 0 to 30 behind each observation will be used to create ts_fresh metrics.
- Min Timeshift:
The minimum value at which the window will be looked at for each observation. Example: min_timeshift = 10, all windows above 10 will be used up to the max_timeshift backwards of each observation to create ts_fresh metrics
- Group by:
The field based on which the features must be calculated.
- Timestamp:
The name of the Timestamp column in the dataset. You must enter the Timestamp column name as in the dataset.
- Large:
Indicates whether you want to run large ts fresh features. Possible values are true and false. Selecting True runs large ts fresh features and false runs only few ts fresh features.
The sample input for this transform looks as shown in the screen shot:
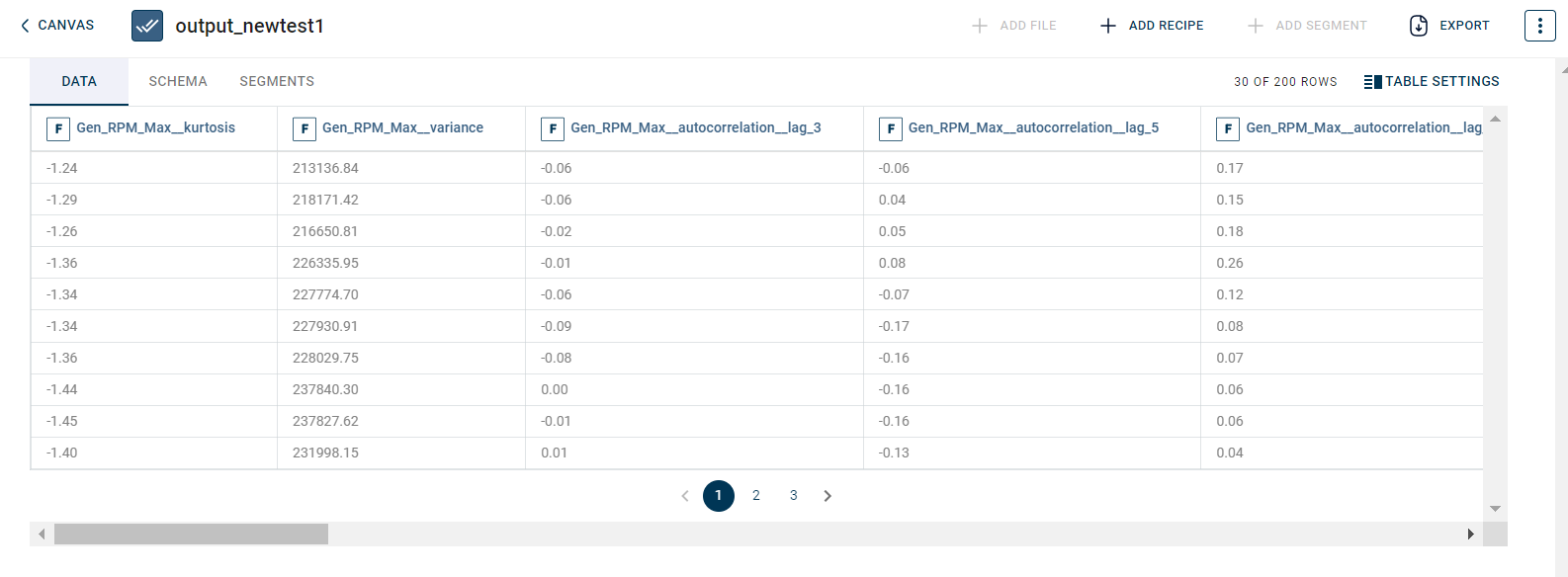
The output after running the Tsfresh features transform on the dataset appears as below.
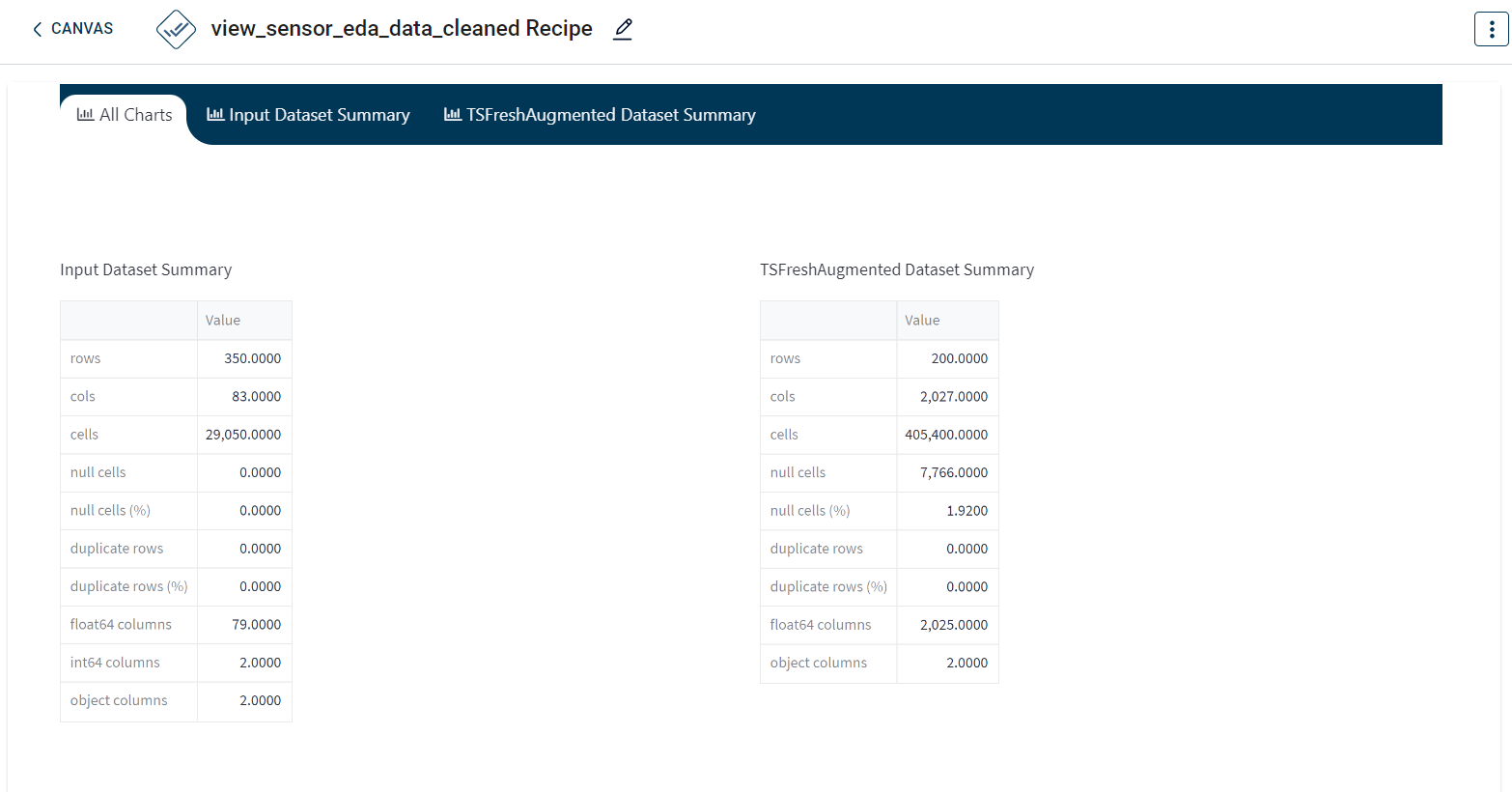
The dashboard output for Tsfresh features appears as below. This provides the number of rows, columns, null cells, total cells, duplicate rows and float64 columns in the output dataset.
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Truncate dataset transform:
sensor_tsfresh = project.addRecipe([sensor_cleaned], name='sensor_tsfresh')
tsfresh = Transform()
tsfresh.templateId = tsfresh_template.id
tsfresh.name='tsfresh'
tsfresh.variables = {
'inputDataset': "sensor_cleaned",
"max_timeshift":30,
"min_timeshift":30,
"entity":'Turbine_ID',
"time":'Timestamp',
"large":"True",
"outputDataset": "sensor_ts_fresh"
}
sensor_tsfresh.add_transform(tsfresh)
sensor_tsfresh.run()
Requirements
pandas