Data quality
This transform checks for issues in the dataset and displays the first five rows, last five rows in the dataset, rows & columns size, missing values, data types, duplicates, cardinality, duplication rate, column name analysis, normality, and other potential data errors.
tags: [“Data Preparation”]
Parameters
The table gives a brief description about each parameter in Data quality transform.
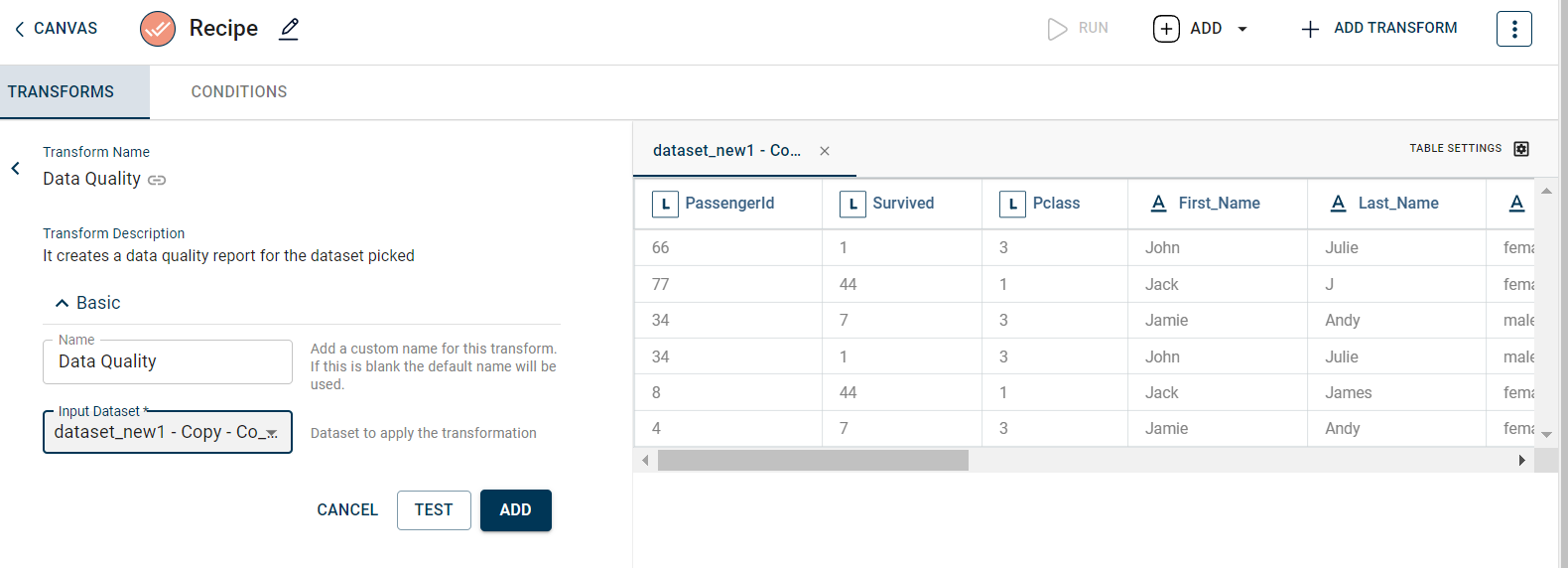
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Input Dataset:
The file name of the input dataset. You can select the dataset that was uploaded from the drop-down list to check its data quality. (Required: True, Multiple: False)
The sample input for this transform looks as below:
The output after running the Data quality transform on the dataset appears as below:

How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Data quality transform:
Requirements
pandas