Random forest
This transform will use the Random forest algorithm to create machine learning models for classification and regression problems in a dataset and returns the data with predictions.
tags: [“model building”, “model prediction”]
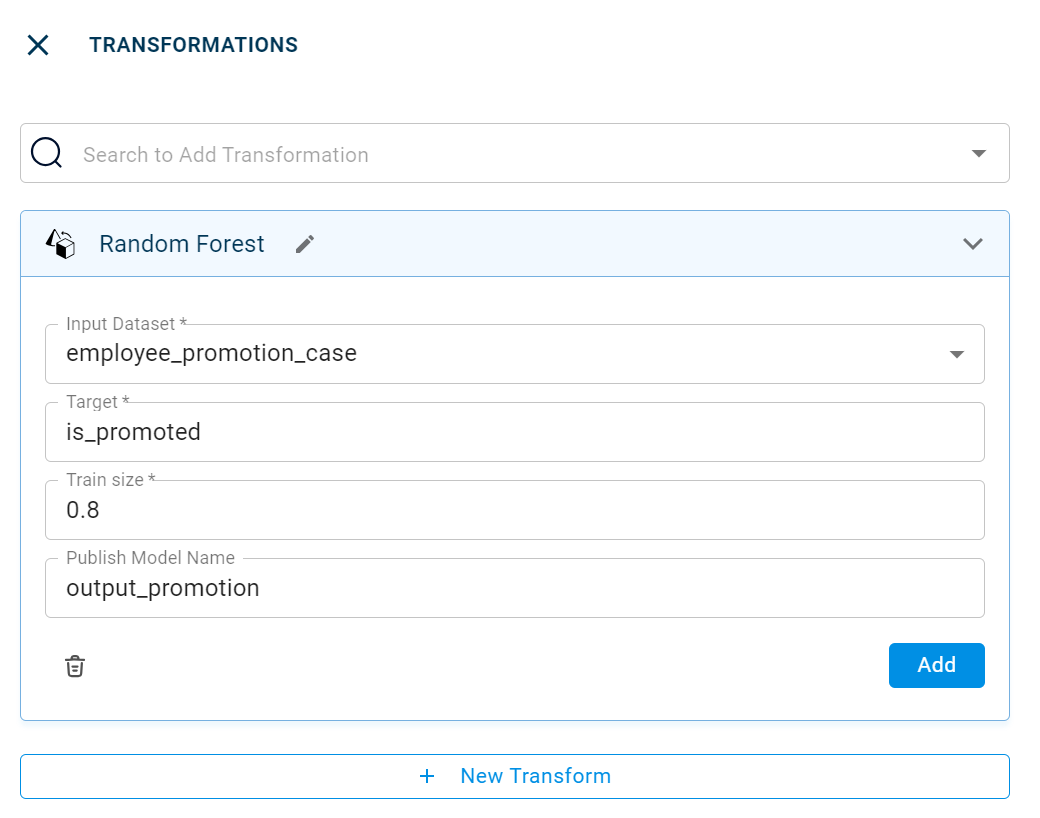
Parameters
The table gives a brief description about each parameter in Random forest transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
:Input dataset:The file name of the input dataset. You can select the dataset that was uploaded from the drop-down list.
- Target:
The target column on which predictions should be made.
- Train size:
The data to be considered for training.
- Publish model name:
The name with which the created model is published.
The sample input for this transform looks as shown in the screenshot:
The output dataset created after running the Random forest transform on the dataset appears as below. This creates a model and shows the predictions made on the train data.

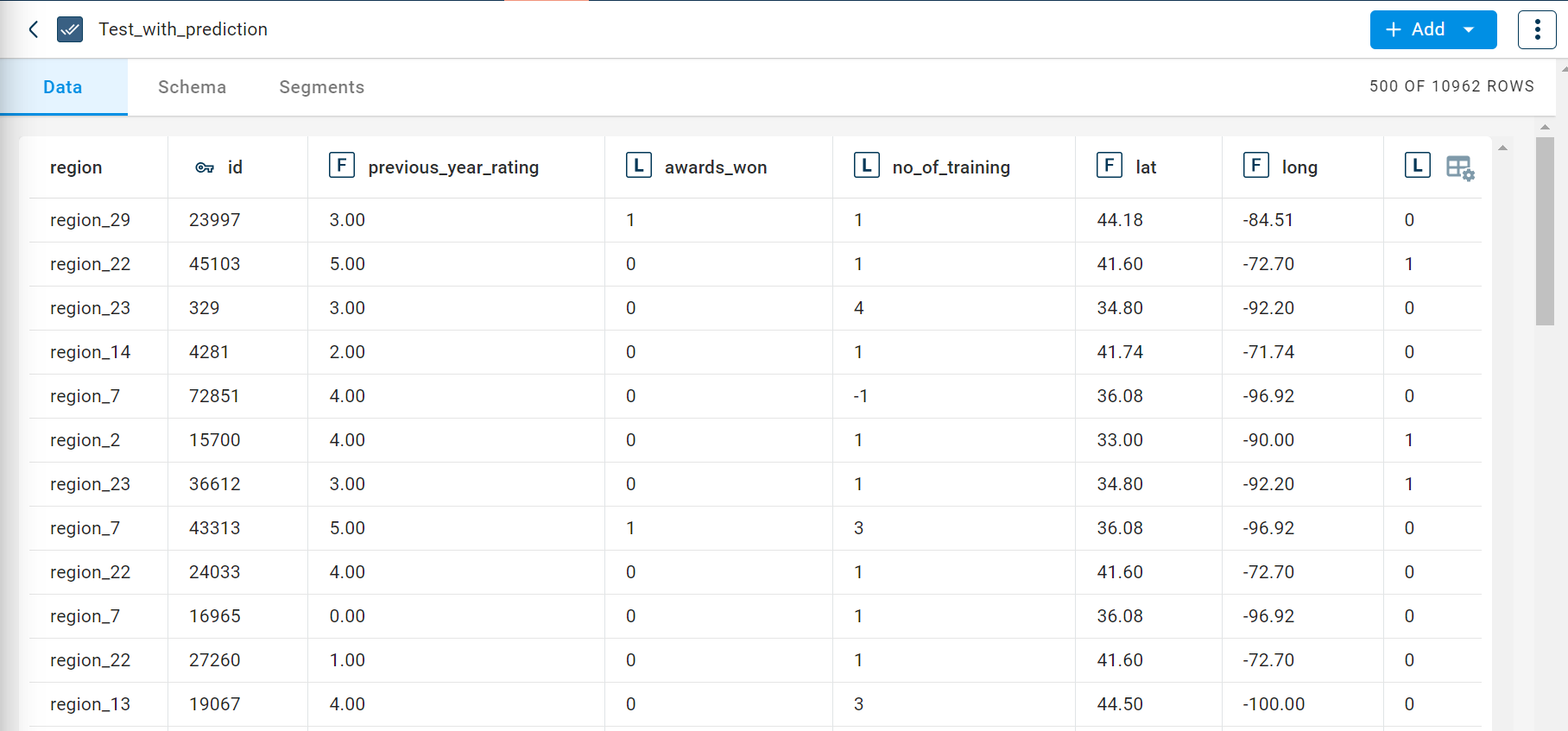
The output dataset created after running the Random forest transform on the dataset appears as below. This shows the test prediction that is made based on the model created with the train data.
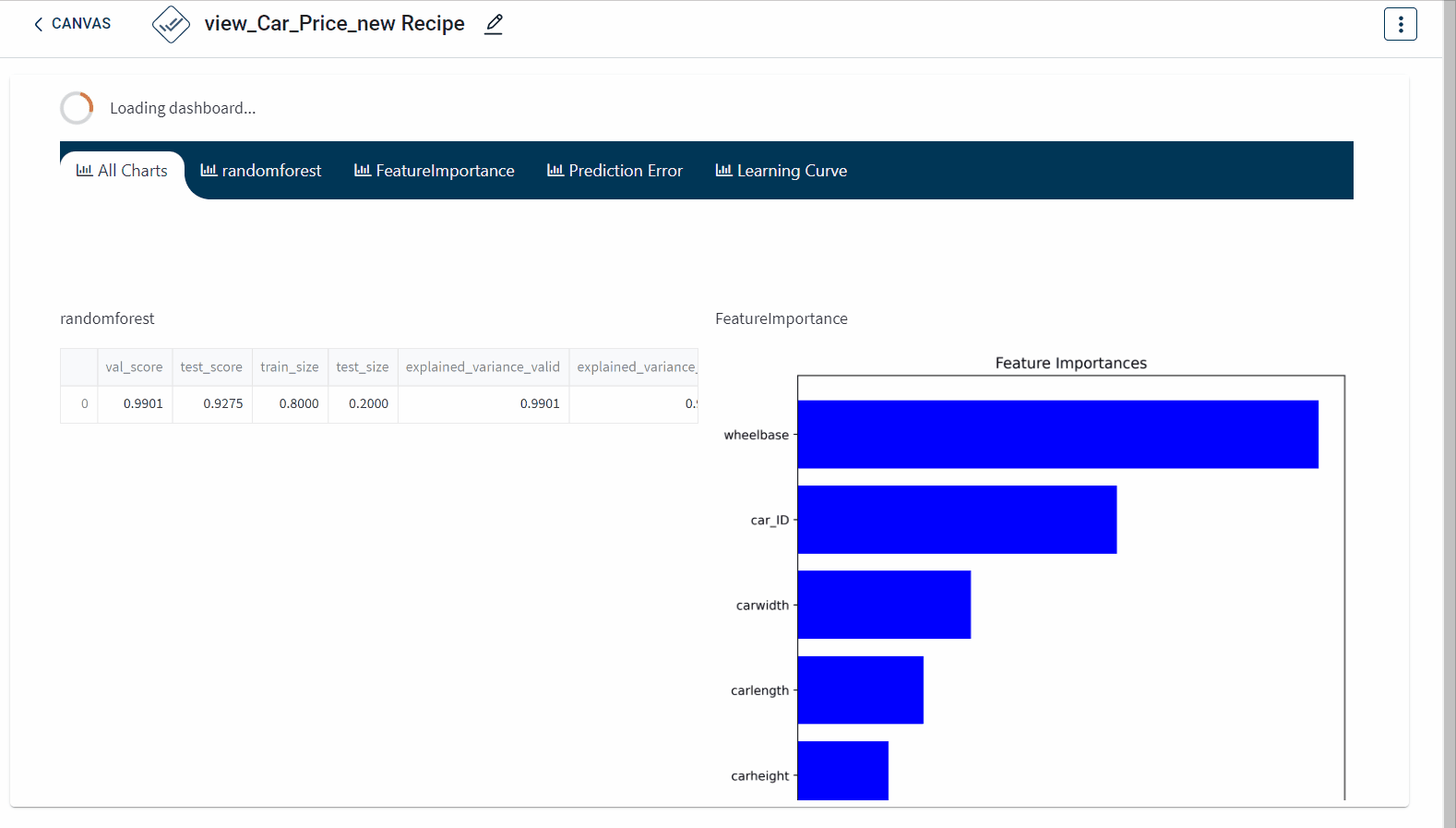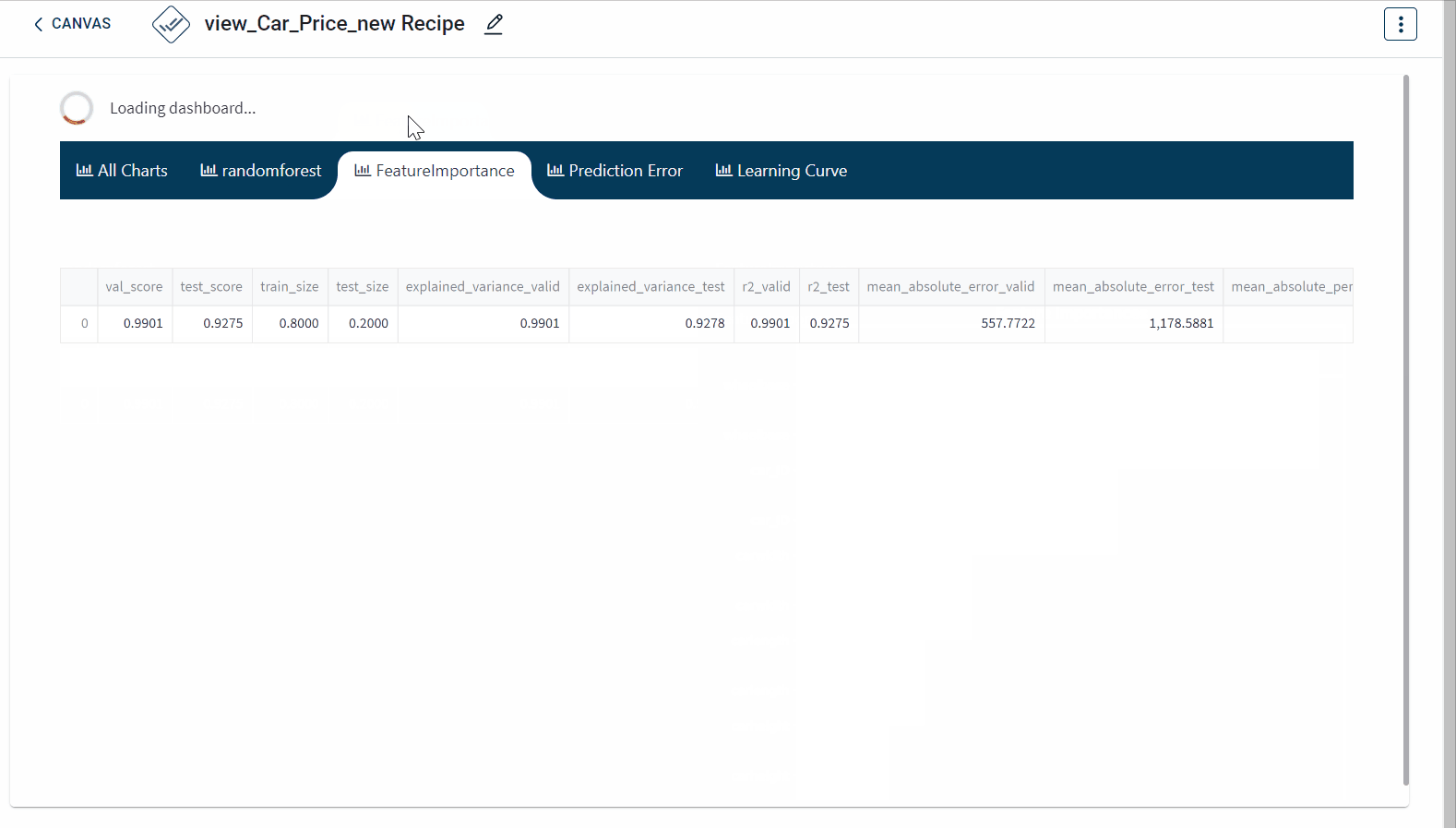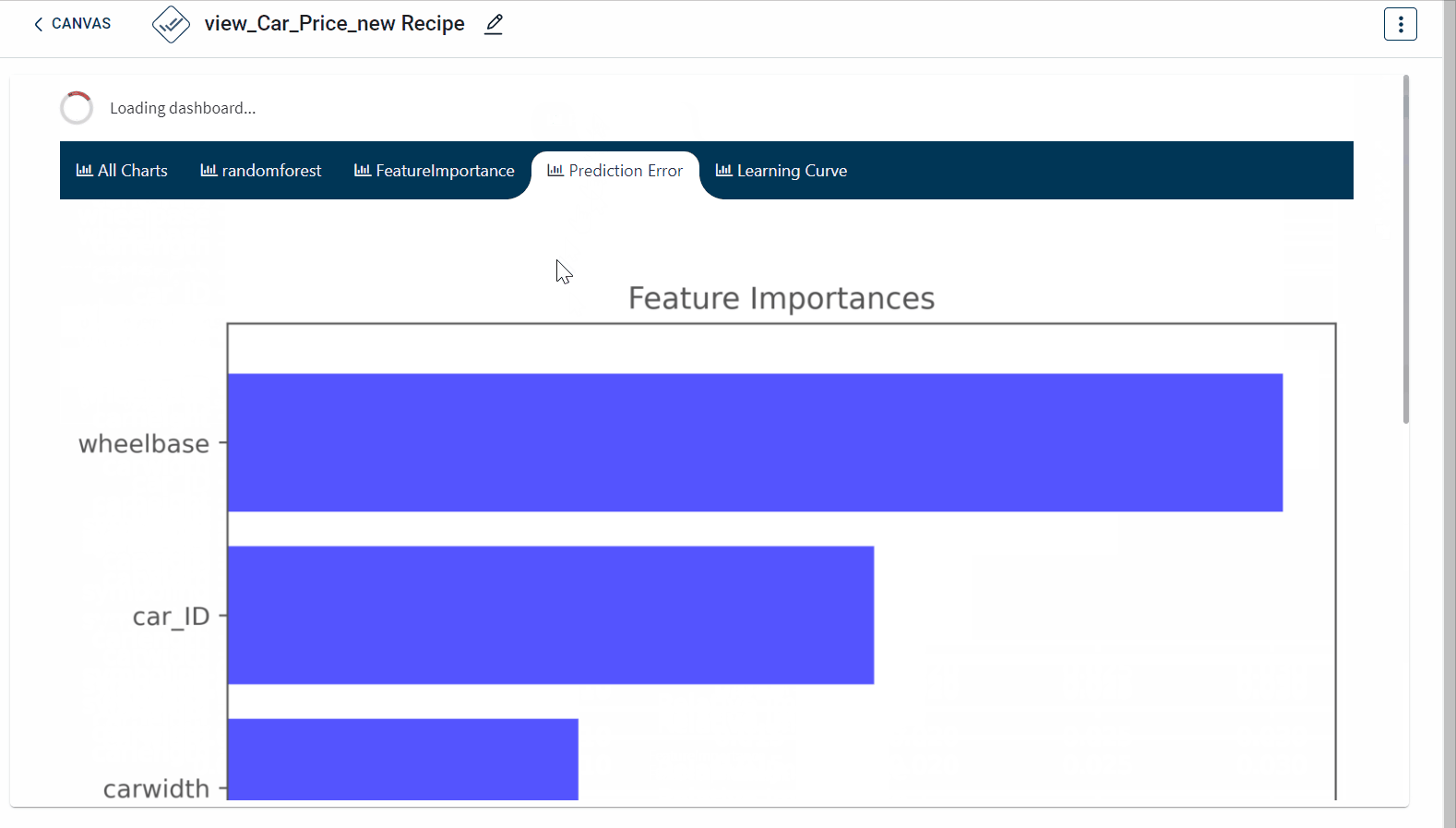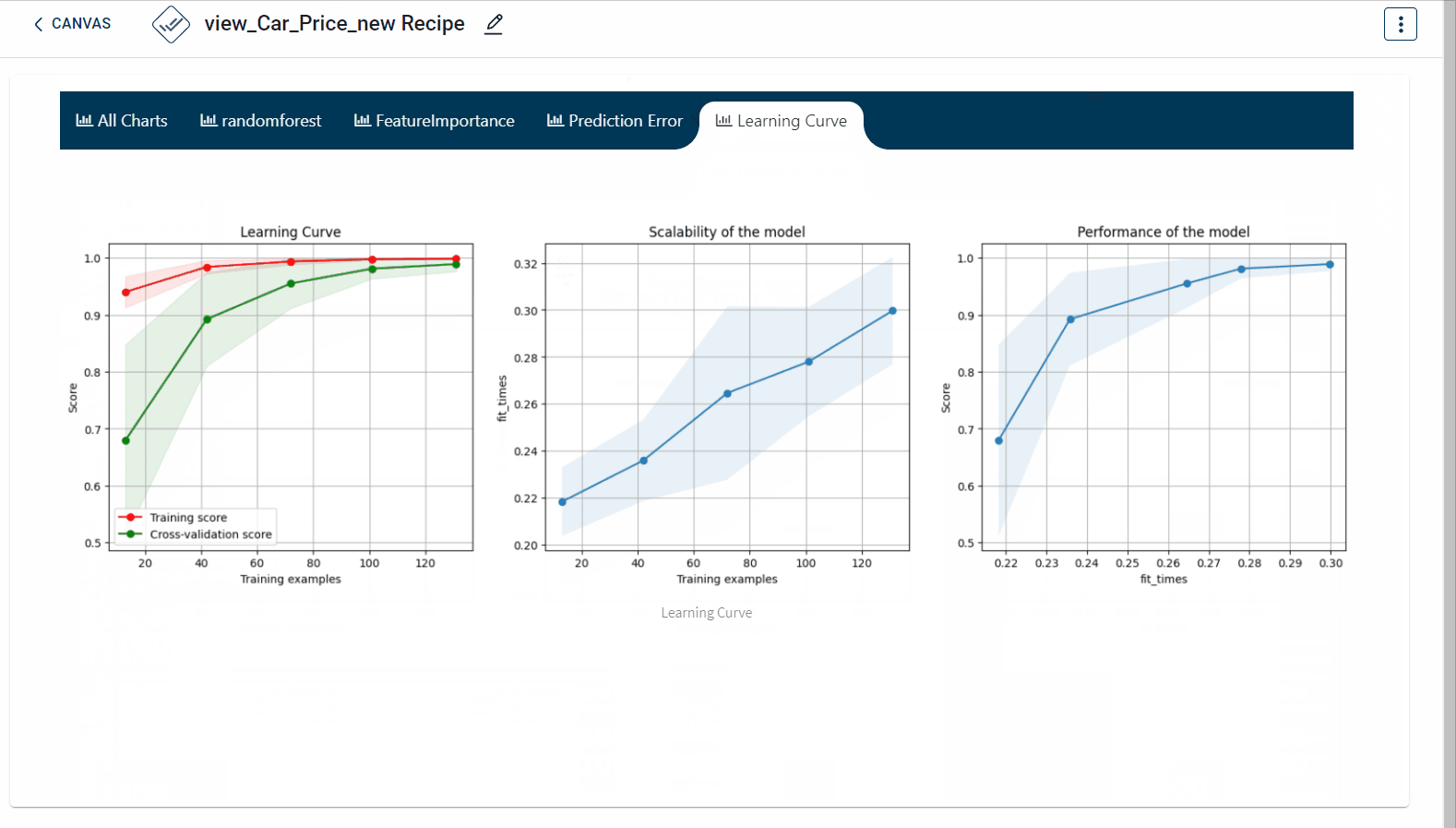
The dashboard created appears as below:
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Random forest transform:
Requirements
scikit-learn pandas