Frequency encoding
This transform calculates the frequency of each unique value in the columns of a dataset based on the cardinality cutoff value. If the cutoff value is 2, this picks all the columns with less than or equal to 2 unique values in the dataset and calculates the frequency count of every unique value in the column along with the percentage.
tags: [“Feature engineering”]
Parameters
The table gives a brief description about each parameter in Frequency encoding transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Train Dataset:
The train dataset on which frequency encoding is performed.
- Test Dataset:
The test dataset on which frequency encoding is performed.
- Cardinality cutoff:
The cut off value is a threshold value to consider a column as a category or not.
:Target column:The target column on which predictions are made. This should be kept intact in feature engineering.
- Original Dataset Name:
The name of the original dataset to extract the meta data.
- Output Train Dataset:
The file name with which the output train dataset is created. This file creates new columns with frequency count of each value and percentage count to the categorized columns.
- Ouput Test Dataset:
The file name with which the output test dataset is created. This file creates new columns with frequency count of each value in the categorized columns along with the percentage of each unique value in the column.
The sample input for this transform looks as shown in the screenshot.
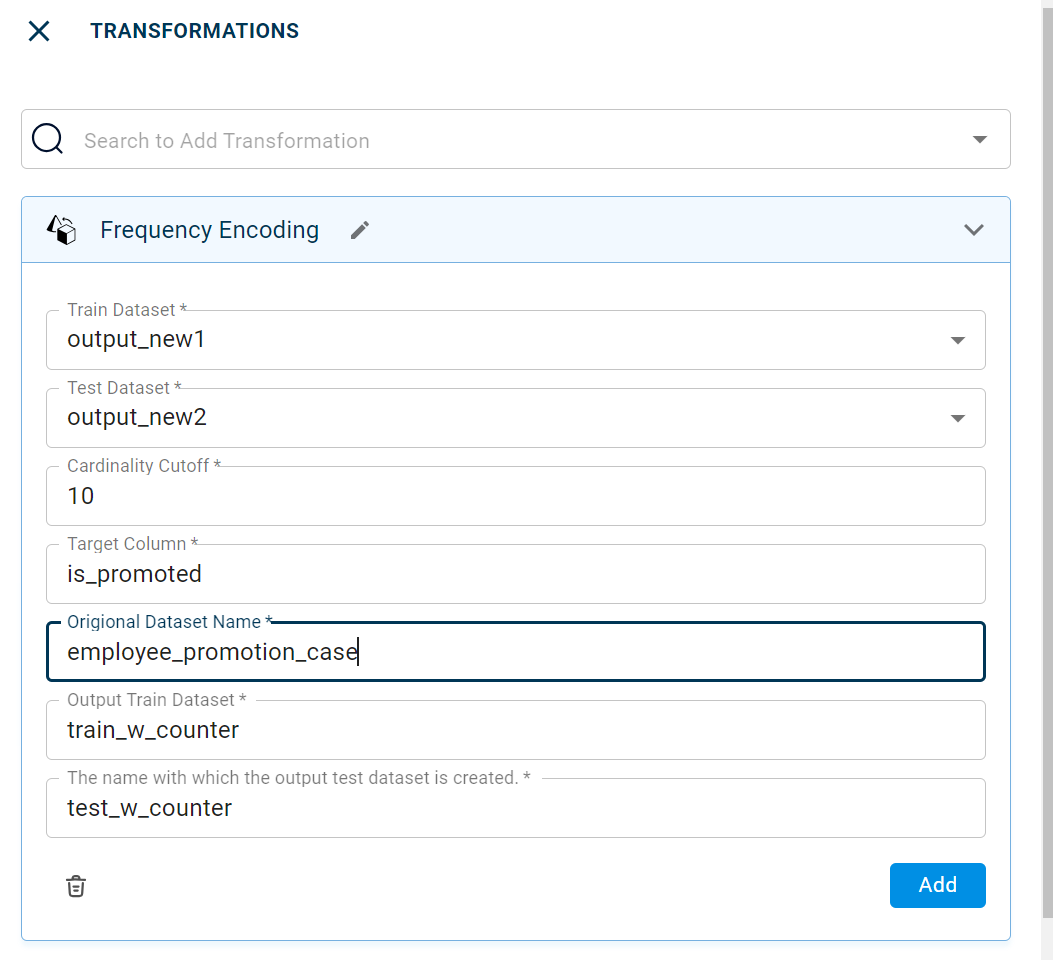
The output after running the Frequency encoding transform on the test dataset appears as below:
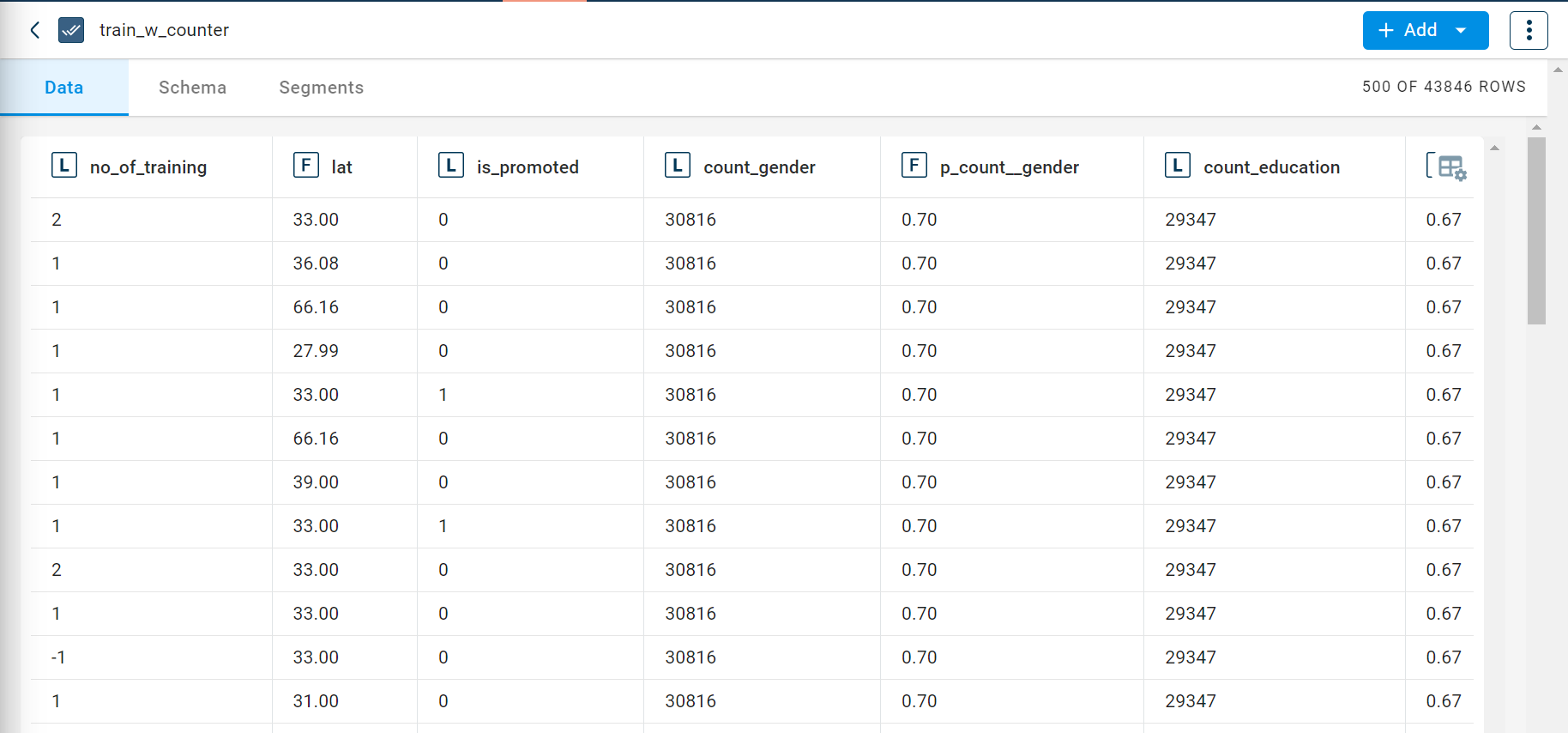
The output after running the Frequency encoding transform on the train dataset appears as below:

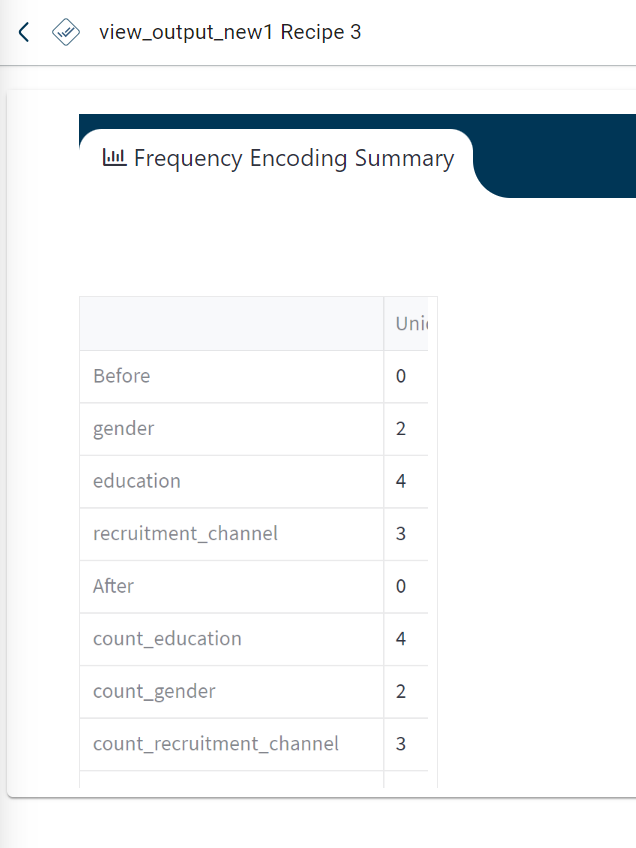
The dashboard output for frequency encoding appears as below with the list of unique values in each column:
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Frequency encoding transform:
transform = Transform()
transform.name = "frequency encoding"
transform.templateId = freq_encoding.id
transform.variables = {
"inputTrainDataset": train_w_agg.name,
"inputTestDataset": test_w_agg.name,
"cardinalityCutoff": 10,
"targetCol": targetCol,
"origionalDatasetName": dataset_input_name,
"outputTrainDataset": freqe_train_ds_name,
"outputTestDataset": freqe_test_ds_name
}
recipe_freq = project.addRecipe([train_w_agg, test_w_agg], name="frequency_encoding")
# recipe_freq.prepareForLocal(transform, contextId="recipe_freq")
recipe_freq.addTransform(transform)
recipe_freq.run()