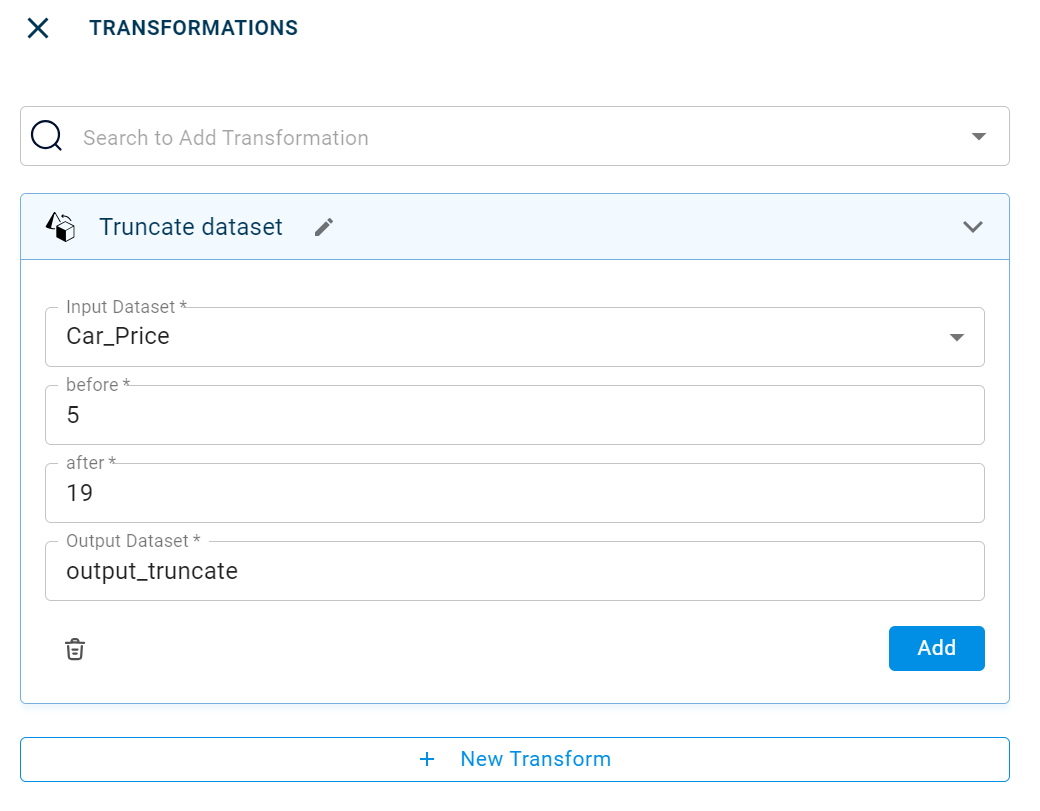
Truncate dataset
This transform returns the rows for the specified index range and removes the rows that are before and after the given index values.
tags: [“Data Preparation”]
Parameters
This table provides a brief description about each parameter in Forward Fill transform.
- Name:
By default, the transform name is populated. You can also add a custom name for the transform.
- Input Dataset:
The file name of the input dataset on which transpose transform must be applied. You can select the dataset that was uploaded from the drop-down list to filter the rows based on the specified index range. (Required: True, Multiple: False)
- Output Dataset:
The file name with which the output dataset is created. This file contains the truncated Dataset. (Required: True, Multiple: False)
- before:
The rows to be truncated from the dataset before this value. (Required: True, Multiple: False, Datatypes: [‘ANY’], Options: [“FIELDS”], Datasets: [“df”])
- after:
The rows to be truncated from the dataset after this value. (Required: True, Multiple: False, Datatypes: [‘ANY’], Options: [“FIELDS”], Datasets: [“df”])
- axis:
Indicates whether to filter by rows or columns. By default, the value should be set to 0. You can select from these options:
0 for “rows”
1 for “columns” (Required: True, Multiple: False, Datatypes: [“LONG”] , Options: [“CONSTANT”], Constant_options: [0,1])
The sample input for this transform looks as shown in the screenshot:
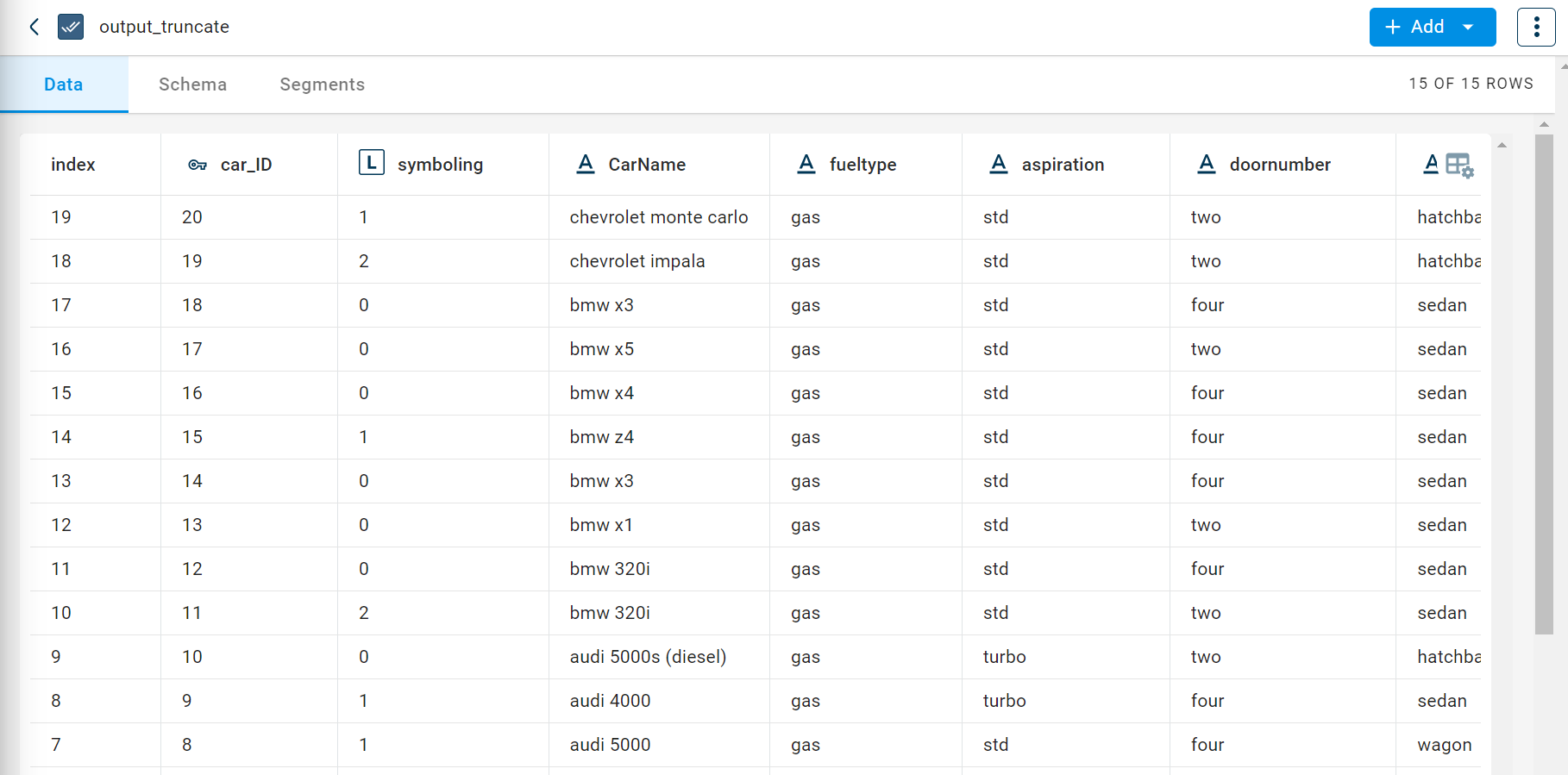
The output after running the Truncate dataset transform on the dataset appears as below.
How to use it in Notebook
The following is the code snippet you must use in the Jupyter Notebook editor to run the Truncate dataset transform:
template=TemplateV2.get_template_by('Truncate dataset')
recipe_Truncate_dataset= project.addRecipe([car_data, employee_data, temperature_data, only_numeric], name='Truncate dataset')
transform=Transform()
transform.templateId = template.id
transform.name='Truncate dataset'
transform.variables = {
'input_dataset':'car',
'output_dataset':'car_truncated',
'value_1':"aspiration",
'value_2':"doornumber",
'value_3':1}
recipe_Truncate_dataset.add_transform(transform)
recipe_Truncate_dataset.run()
Requirements
pandas